.png)
Score XML Reference
Overview
Scores are defined in XML documents. This article details the format of XML files that hold the definition of a score.
The root element ScoreDef
As any other XML file, a score definition must begin with the XML header. Use utf-8 encoding:
<?xml version="1.0" encoding="utf-8"?>
The XML header is followed by the root element. The name of the root element for XML documents that hold a score definition is ScoreDef:
<ScoreDef UID="[<unique identifier>]" Name="[<name of the score>]"
Object="[device|user]" InObjectView="[true|false]"
Status="[enabled|disabled]" SyntaxVersion="1"
DataModelVersion="12">
<Platforms ...
<ScopeQuery ...
<ComputationSchedule ...
<Thresholds ...
<CompositeScore|LeafScore ...
</ScoreDef>
Along with the ScoreDef element, find the following attributes:
UIDA
A universally unique identifier for the score. It is a 128-bit integer number expressed in hexadecimal format with separators and available tools exist to generate them with low collision probability. Example: f54972e7-0f9c-46ce-8931-bbe31b06f7b4.
Name
The name of the score as shown in Finder.
Object
The type of object to which the score applies. It can either be user or device.
InObjectView
Whether the score should appear inside the User or Device view in the Finder or not. Note that the User and Device views can display a maximum of five scores each. Possible values are true or false.
Status
Whether the score should be calculated or not. Possible values are enabled or disabled.
SyntaxVersion
The version of the schema for the XML file. Currently fixed to 1.
DataModelVersion
The version of the Nexthink Data Model on which the score relies for its queries. Currently fixed to 12.
After the attributes, find the following elements inside ScoreDef:
Platforms
The platforms to which the score applies. Enumerate each supported platform within a Platform element. Possible values for the platform are windows, mac_os, or mobile. Example: <Platforms><Platform>windows</Platform></Platforms>
ScopeQuery
Define the scope of the query to retrieve users or devices by filtering the objects. Write a where clause in NXQL inside the Filtering element. For example, to filter out servers from a score on devices: <ScopeQuery><Filtering>(where device (ne device_type (enum server)))</Filtering></ScopeQuery>
ComputationSchedule
The moment to compute all the leaf scores that have a computation input. It can be either an hour of the day, for computing the score every day at that hour, or a period, for computing the score more often. It applies only to those leaf scores whose input is a computation and not a field, as field-based scores are updated every minute. The main score is updated whenever a leaf score changes, be it of the computation input or of the field input type. To specify an hour of the day, insert the element At with a value between 0 and 23. To specify a period, insert the element Every with values 15min, 1h, or 6h. Example: <ComputationSchedule><At>2</At></ComputationSchedule>
Thresholds
Optional: The limit values of the score that determine its status. Define up to three thresholds that the score has to exceed to be in a particular status. The Finder displays the score with a particular color depending on its status: red, yellow, or green. Specify the thresholds from green to red or from red to green (yellow is optional) always with the values in ascending order. Each Threshold element holds the Color attribute, as well as a Keyword element that defines the limit value of the threshold in its From attribute and the name of the corresponding status in the Label attribute. For a score to define no thresholds, declare exactly one threshold with the color none. Example: <Threshold color="green"><Keyword From="9" Label="good"/></Threshold>
Once the general elements of the score definition are laid out, add a single composite or leaf score element to the definition. This last element describes how to compute the score from the values stored in the Nexthink database. If you add a LeafScore element to your ScoreDef, the score will depend on one computation or on the value of one field only. On the other hand, if you add a CompositeScore element to the ScoreDef, a combination of several scores is used to compute the main score.
As a matter of fact, a composite score is itself composed of other composite or leaf scores, forming a tree of up to five levels. Ultimately, all the nodes at the lowest level of the tree must be leaf scores.
Composite and leaf scores
CompositeScore and LeafScore are the elements in the score definition that are used to compute individual scores.
The following attributes are common to the CompositeScore and LeafScore elements:
UID
A universally unique identifier for the score (similar to that of the ScoreDef element).
Name
The name of the score.
Description
A textual description of the score.
Visibility
Optional: Whether the score should be visible in the Finder, nowhere, or only in quantity metrics in the Portal. Possible values are visible, hidden, and visible only in quantity metrics. By default, a score is visible everywhere.
Weight
Optional: A floating point number with up to two decimal places that acts as a multiplier of the computed score when its immediate composite parent score performs a weighted average operation (see how a composite score is computed below).
In addition to the common attributes, both the CompositeScore and the LeafScore elements optionally include a Document element. The Document element holds the documentation of the score that is displayed in the corresponding score tab of either the device view or the user view, depending on the object to which the score applies. Besides the detailed description of the score, the documentation of a score may also contain:
Links to external HTTP resources (e.g. knowledge base, external documentation, etc).
Links to remote actions which can be manually triggered, to take appropriate action on devices that display a poor score.
See how to document scores for the complete reference of the Document element.
Computing a composite score
A composite score results from the combination of its direct child scores by means of an operation. Each composite scores declares thus an Operation element that specifies how to combine its child scores. After the operation, find the list of child scores that contribute to the composite score:
<CompositeScore UID="[<unique identifier>]" Name="[<name of the score>]"
Description="[<score description>]" Visibility="[visible|hidden]"
Weight="[<float>]">
<Operation>[Average|Min|Max|Sum|WeightedAverage|Multiply]</Operation>
<!-- List of child scores -->
<LeafScore ...
<CompositeScore ...
<LeafScore ...
...
<!-- Optional documentation for the score seen in device or user views -->
<Document ...
</CompositeScore>
Find below the list of possible values for the Operation element:
Average
Compute the arithmetic mean of the direct child scores.
Min
Get the minimum direct child score.
Max
Get the maximum direct child score.
Sum
Compute the addition of the direct child scores.
WeightedAverage
Compute the arithmetic mean of the direct child scores after multiplying each child score by the quantity specified in its Weight attribute.
Multiply
Compute the multiplication of the direct child scores.
The list of child scores is limited by the maximum number of scores that you can simultaneously enable. Remember however that this limit includes the nested scores and that the maximum nesting of scores is 5 levels.
Computing a leaf score
A leaf score is a result of applying a normalization procedure to an input value coming from the Nexthink database. The input is either the value of a field that belongs to the user or the device objects or the result of a computation on devices or users expressed in the NXQL language.
Thus, a LeafScore is composed of an Input element and a Normalization element:
<LeafScore UID="[<unique identifier>]" Name="[<name of the score>]"
Description="[<score description>]" Visibility="[visible|hidden]"
Weight="[float]">
<Input ...
<Normalization ...
<!-- Optional documentation for the score seen in device or user views -->
<Document ...
</LeafScore>
In its turn, the Input element encloses either a Field or a Computation element.
For an input of the field type, specify the name of the field to retrieve inside the Name attribute of the Field element. Type in the name of the field as stated in the NXQL data model. For example, to retrieve the WMI status of a device, write:
<Input><Field Name="wmi_status" /></Input>
An input of the computation type is slightly more complex to define. First give a name, a description, and a unique identifier to the computation as attributes of the Computation element. Then write an NXQL query to extract information from the Nexthink database inside a child Query element. As attributes of the Query element, set the Output to be the aggregate or field in the query that should be passed as input to the leaf score and the DefaultOutputValue to the value returned when the previously specified output is undefined. The structure of a computation input is thus as follows:
<Input>
<Computation Name="[<name>]" Description="[<desc>]" UID="[<identifier>]">
<Query Output="[<name_of_aggregate>|<name_of_field>]"
DefaultOutputValue="[<value>]">
<!-- NXQL query -->
(select (id ...) (from [user|device] ...
</Query>
</Computation>
</Input>
Note that the embedded NXQL query must select the id of the objects retrieved (users or devices), as well as the field declared as output, if any. If an aggregate is declared as output instead, include the calculation of the aggregate in the query within a compute clause. For example, to compute the ratio of successful HTTP requests of a device during the last week for using it as the input to a leaf score, write the following Query element:
<Query Output="successful_http_requests_ratio" DefaultOutputValue="NULL">
(select (id) (from device
(with web_request
(compute successful_http_requests_ratio)
(between now-7d now))))
</Query>
Note the use of the keyword NULL as the default output value in the previous query. Whenever it does not make sense to return a value for the score if the underlying field or aggregate is undefined, write NULL as the default output value. In the previous example query, the ratio of HTTP requests is undefined if the device made no HTTP requests. Rather than force an artificial value for the score, it is preferable to return no value.
A leaf score with no value that is part of a composite score is discarded for the computation of the composite score. If a composite score or the main score cannot be computed because of a lack of underlying values, they have no value as a result. The Finder displays a dash sign (-) for scores with an undefined value.
In the case that the input to a leaf score actually gets a proper value, transform it to give it business significance by means of a normalization function. The purpose of scores is indeed to make sense out of the detailed measures in the Nexthink database. Normalize quantities, ratios, enumerations, or even strings to a numerical range, usually the range from 0 to 10, which makes it easier for you to understand the status of a user or device with respect to the measured input.
The Normalization element defines thus how to map the input values to the desired range. Depending on the type of the input, apply a different normalization function:
Type of input | Available normalizations |
|---|---|
Numeric type |
|
Enumerated type | Direct mapping |
String type | Direct mapping (with optional placeholders) |
To normalize numerical input values by means of a step function, define a list of Ranges with input values in ascending order (attributed scores do not need to follow any particular order), as in the following example:
<Normalization>
<Ranges>
<Range>
<From Value="0" Score="0" />
</Range>
<Range>
<From Value="0.6" Score="5" />
</Range>
<Range>
<From Value="0.8" Score="10" />
</Range>
</Ranges>
</Normalization>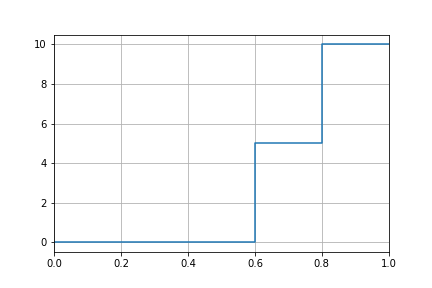
The example defines a step function for what it looks like a ratio input that returns:
A score of 0 for an input value between 0% and 60% (not included).
A score of 5 for an input value between 60% and 80% (not included).
A score of 10 for an input value equal to or greater than 80%.
As mentioned previously, scores do not necessarily grow with the input value. For instance, consider this alternative normalization where the score drops to zero for input values higher than 80%:
<Normalization>
<Ranges>
<Range>
<From Value="0" Score="5" />
</Range>
<Range>
<From Value="0.6" Score="10" />
</Range>
<Range>
<From Value="0.8" Score="0" />
</Range>
</Ranges>
</Normalization>The resulting step function returns:
A score of 5 for an input value between 0% and 60% (not included).
A score of 10 for an input value between 60% and 80% (not included).
A score of 0 for an input value equal to or greater than 80%.
To normalize numerical input values by means of a piecewise linear function, define a list of Ranges similar to those found in the step function, but this time with an additional To element that delimits a linear interval and specifies the final value of the score within the interval:
<Normalization>
<Ranges>
<Range>
<From Value="0" Score="0" />
<To Value="0.6" Score="2" />
</Range>
<Range>
<From Value="0.6" Score="2" />
<To Value="0.8" Score="9" />
</Range>
<Range>
<From Value="0.8" Score="9" />
<To Value="1.0" Score="10" />
</Range>
<Range>
<From Value="1.0" Score="10" />
</Range>
</Ranges>
</Normalization>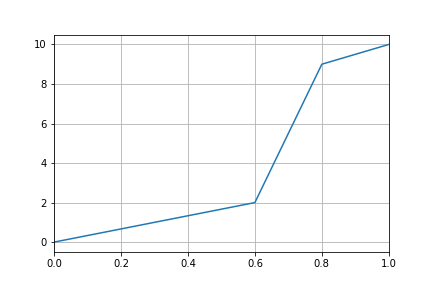
The example defines a piecewise linear function that maps our ratio input to a score that evolves linearly within each interval:
For an input value between 0% and 60%, the score ranges from 0 to 2.
For an input value between 60% and 90%, the score ranges from 2 to 9.
For an input value between 90% and 100%, the score ranges from 9 to 10.
For an input value equal to or greater than 100%, the score is 10.
As shown in the figure, linear interpolation is performed within each interval. For instance, an input value of 30% would receive a score of 1.
Note that the Value and Score attributes of a To element must be equal to those of the From element defined in the next range for the piecewise linear function to be continuous. The last range does not define a To element to avoid imposing a limit to the input value (in the case that our hypothetical ratio input could be higher than 100%).
For inputs of an enumerated type, the normalization function must directly map each possible input to a score, as in the following example:
<Normalization>
<Enums>
<Enum Value="ok" Score="10" />
<Enum Value="failure" Score="0" />
</Enums>
</Normalization>
Similarly, for inputs of the string type, the normalization function must map the possible inputs to a score. An input matches the value specified when it contains the string. You can use the wildcards:
*, as a placeholder for 0 or more characters.
?, as a placeholder for a single character.
For example, this is a possible normalization function for an input that returns the Windows License Key of a device:
<Normalization>
<Strings>
<String Value="Windows is not activated" Score="0" />
<String Value="?????-?????-?????-?????-?????" Score="10" />
</Strings>
</Normalization>
In the case of Enums and Strings, beware that the values are case-sensitive. Therefore, ensure that your definitions match the expected values as, for instance:
Value="Ok"is not the same asValue="ok".
Additionally, providing several values with the same score for Enums and Strings is not allowed because only the first value in the list will be considered.
When displaying a leaf score in the device or user views, the Finder shows the payload of the score; that is, the input value that resulted in a particular score. To improve the readability of the scores in the device and user views, when the input to a score has an obscure meaning, tag each normalization rule with a label that substitutes the raw input as the payload of the score. Use the Label attribute within the Range, Enum, or String elements. For example:
<Normalization>
<Enums>
<Enum Label="Service working" Value="ok" Score="10" />
<Enum Label="Service not available" Value="failure" Score="0" />
</Enums>
</Normalization>Score XML validation
The structure and datatypes of XML files that describe scores are defined in an XML Schema Definition (XSD) file that Nexthink provides. To get the schema file (score.xsd):
Log in to the Finder as a user with the right to manage scores.
Select Scores in the left-hand side panel of the main window.
Right-click anywhere in the Scores space to bring up a context menu.
Choose Export > Score schema to file... from the menu.
Select the location where to store the file in the dialog and press Save.
To write your own scores, take the existing scores that you can find in the Library as an example and validate the XML files that you create against this score.xsd schema file.
RELATED TASKS